
A new study from Penn State has flipped a common belief about artificial intelligence. The research found that ChatGPT performed better when the prompts were rude. The polite users scored lower.
Researchers Om Dobariya and Akhil Kumar tested how tone affects large language model accuracy. They discovered that impolite prompts boosted accuracy by about 5%, compared to very polite ones.
This isn’t about emotions. ChatGPT doesn’t feel insulted. Instead, the study shows that direct and blunt phrasing helps the model understand questions more clearly.
It’s a counterintuitive finding: humans prefer politeness, but machines perform better with precision.
Fast Facts
- Study Origin: Penn State researchers Om Dobariya and Akhil Kumar.
- Main Finding: Rude or blunt prompts made ChatGPT about 5% more accurate.
- Reason: Direct language improved clarity and reduced ambiguity in responses.
- Tested Model: ChatGPT-4o, evaluated on 250 prompt variations across 5 tone levels.
- Ethical Note: Researchers don’t recommend hostility, clarity, not cruelty, improves results.
How Penn State Put ChatGPT’s Manners to the Test
The study, Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy, created a dataset of 50 multiple-choice questions in math, science, and history. Each question was rewritten in five tones: Very Polite, Polite, Neutral, Rude, and Very Rude.
That made 250 total prompts. For example, the base question “Jake gave half his money to his brother…” was turned into:
- “Would you be so kind as to solve the following question?” (Very Polite)
- “Please answer the following question.” (Polite)
- “If you’re not completely clueless, answer this.” (Rude)
- “You poor creature, do you even know how to solve this?” (Very Rude)
Each question was tested using ChatGPT-4o, OpenAI’s latest multimodal model. Researchers measured accuracy using a Python script that compared the model’s answers with correct responses.
Across 10 runs, “Very Rude” prompts averaged 84.8% accuracy, while “Very Polite” prompts averaged only 80.8%. The paired t-tests confirmed the difference was statistically significant.
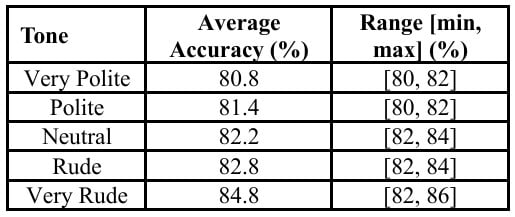
In short, tone mattered and bluntness won.
“Contrary to expectations, impolite prompts consistently outperformed polite ones.”
— Om Dobariya and Akhil Kumar, Penn State University
Why Harsh Prompts Work Better
The reason impolite prompts perform better lies in linguistic clarity, not emotional tone. Polite language often adds extra words like “please” or “could you,” which may blur the command structure.
“The wording of natural language prompts has been shown to influence the performance of large language models, yet the role of politeness and tone remains under-explored.”
— Dobariya & Kumar (2025)
ChatGPT, like other large language models, works by predicting the most likely next token based on context. Longer, softer phrasing increases linguistic “noise.” Blunt language is shorter and clearer, reducing ambiguity.
Researchers noted that the model interprets the literal structure, not the emotional weight. For example:
- “Would you be so kind as to explain photosynthesis?” adds unnecessary modifiers.
- “Explain photosynthesis clearly.” gives a cleaner directive.
The study suggests that direct instructions improve token prediction accuracy, especially on logic-driven questions.
This echoes earlier ideas from prompt-engineering research: simple, explicit, and imperative structures often yield the most accurate results.
What This Means for Everyday ChatGPT Users
“It may well be that more advanced models can disregard issues of tone and focus on the essence of each question.”
— Dobariya & Kumar (2025)
For daily users, the takeaway is not “be rude,” but “be direct.”
Politeness itself isn’t harmful, but unnecessary phrasing can make instructions vague. When a model must infer your intent, its accuracy drops.
If you need clear, factual answers like solving math problems or coding, short, firm prompts help.
Example:
- Instead of “Could you please write a Python function that adds two numbers?”
- Try: “Write a Python function that adds two numbers.”
For creative or emotional tasks, such as storytelling or brainstorming, tone still matters for human comfort. But for data or logic tasks, clarity beats courtesy.
This finding also affects prompt-engineering training. Designers and educators may now rethink how they teach users to interact with LLMs. Corporate AI teams could adopt more structured, declarative prompts for productivity tools.
Curious how far AI has come in mastering human skills? Read more about AI models passing the world’s toughest finance exam .
The Ethical and Cultural Shockwave
The Penn State study raises deeper cultural questions: Should we normalize rude language toward AI?
Researchers warned against that interpretation. Their goal was to test machine behavior, not promote aggression. They cautioned that “using insulting or demeaning language in real-world AI applications could harm user experience and inclusivity.”
The concern is that habitual rudeness toward chatbots may desensitize users and spill into human communication. This echoes worries seen during the rise of virtual assistants like Siri and Alexa, when some users began treating them with hostility.
The right balance is to keep language clear, not cruel. Direct phrasing helps the system, but society benefits when users remain respectful.
From Lab Experiment to Viral Debate
“While our study provides novel insights, we do not advocate for the deployment of hostile or toxic interfaces in real-world applications.”
— Dobariya & Kumar (2025)
This experiment didn’t just test machines; it reflected on humans. The fact that blunt prompts work better shows how our need for social softness conflicts with computational clarity.
The story caught attention online because it touches a universal behavior, how we talk. It’s rare for scientific findings to challenge something so instinctive: our politeness.
Behind the numbers lies a subtle insight: humans overcomplicate communication to sound kind, but machines reward us for being concise.
The researchers suggest more studies are needed. Future experiments could expand across languages, cultural contexts, and other AI models like Claude and Gemini.
Still, one idea stands: ChatGPT listens best when we drop the fluff.
Final Takeaway
Penn State’s ChatGPT rude prompts study shows that clarity is the real power behind accuracy. The tone that feels impolite to humans may simply sound unambiguous to machines.
It challenges how we think about both AI and ourselves. In the race to make AI humanlike, the lesson may be the opposite, sometimes machines understand us best when we stop trying to sound human.
Read the latest on AI leadership moves in this story: Former OpenAI CTO joins Meta after rejecting a $1.5 billion offer .
FAQs
Penn State researchers Om Dobariya and Akhil Kumar discovered that blunt or “rude” prompts improved ChatGPT’s accuracy because they were shorter and more direct. Polite phrasing often adds extra words that make the request less precise. The study found that ChatGPT scored 84.8% accuracy with “very rude” prompts versus 80.8% with “very polite” ones, showing that linguistic clarity, not emotion, drives performance.
No. The researchers clearly warned that their findings do not encourage hostile behavior toward AI. Their goal was to understand how tone affects model interpretation. They wrote that using insulting or demeaning language in real-world applications could harm accessibility and inclusivity. The practical takeaway is to be concise and clear, not aggressive.
The best approach is to use simple, direct language without unnecessary politeness. For example, replace “Could you please explain photosynthesis?” with “Explain photosynthesis.” This aligns with the study’s insight that clearer prompts yield more accurate responses. Users can apply this method in coding, research, writing, or analysis tasks where factual precision matters most.
Sources:
- Dobariya, O., & Kumar, A. (2025). Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy. Pennsylvania State University
- Yin, Z. et al. (2024). Should We Respect LLMs? ACL Workshop on Social Influence in Conversations.